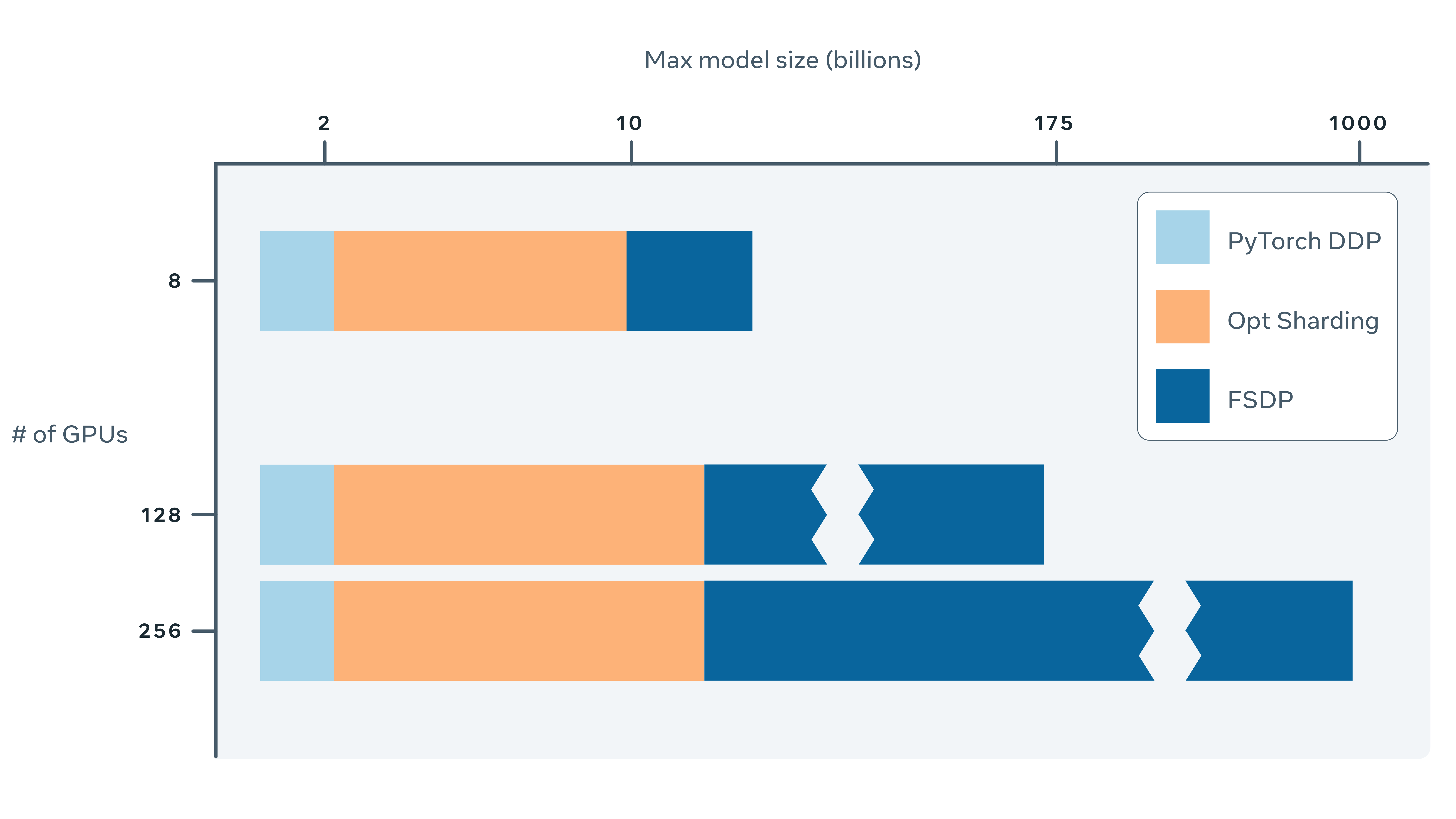
Training AI models at a large scale isn’t easy. Aside from the need for large amounts of computing power and resources, there is also considerable engineering complexity behind training very large models. At Facebook AI Research (FAIR) Engineering, we have been working on building tools and infrastructure to make training large AI models easier. Our [...]
Read More...
The post Fully Sharded Data Parallel: faster AI training with fewer GPUs appeared first on Facebook Engineering.
http://dlvr.it/S3ndNR



Komentar
Posting Komentar